Viele Unternehmen nutzen den Net Promoter Score (NPS), um die Zufriedenheit ihrer Kundinnen und Kunden zu messen. Neben der reinen Punktbewertung auf einer Skala von 0 bis 10 geben Kund:innen häufig zusätzliches Freitextfeedback. Dieses enthält oft konkrete Hinweise zu Service, Produkt oder Kauferlebnis – aber: Die Auswertung dieser unstrukturierten Texte ist aufwändig.
Ausgangslage und Ziel
Im Kern geht es darum, Freitextkommentare aus einer realen NPS-Erhebung eines Onlinehändlers (fast 5000 Einträge) in vier vordefinierte Kategorien einzuordnen:
- Mitarbeiter
- Produkt
- Kauferlebnis
- Sonstiges
Dabei wird nicht nur erkannt, ob ein Thema angesprochen wird, sondern auch, ob es positiv oder negativ erwähnt wird. Ziel ist ein automatisiertes System, das diese Klassifikation zuverlässig übernehmen kann – als Ergänzung oder Alternative zur manuellen Auswertung.
Methoden: Zwei KI-Welten im Vergleich
Untersucht werden zwei Ansätze:
- Machine Learning (klassisch): Hier werden Algorithmen wie Logistische Regression, Naive Bayes, SVM und Entscheidungsbaum genutzt. Die Texte werden vorher in Zahlenwerte umgewandelt (z. B. über TF-IDF oder Bag-of-Words), um vom Algorithmus verarbeitet werden zu können.
- Large Language Models (LLM): Hier kommen moderne KI-Sprachmodelle wie GPT-4 oder Gemini zum Einsatz. Über sogenannte „Prompts“ wird den Modellen erklärt, wie sie die Texte einordnen sollen – inklusive Beispielen (Few-Shot Learning). Die Modelle analysieren die Texte dann direkt im Kontext der vorherigen Beispiele.
Der Datensatz
Die Grundlage ist eine Excel-Datei mit knapp 5000 NPS-Einträgen eines deutschen Onlinehändlers. Für etwa 800 Einträge wurde ein sogenannter „Goldstandard“ erstellt – eine manuell geprüfteKlassifikation durch zwei Personen. Damit lässt sich später die Qualität der automatisierten Ergebnisse messen.
Umsetzung LLM: Prompt Engineering als Schlüssel
Bei den LLMs zeigte sich: Die Qualität der Eingabe („Prompt“) ist entscheidend. In einem ersten Schritt wurde das Modell einfach nur mit einer Aufgabe und Beispielen gefüttert. In einem zweiten Schritt wurde der Prompt deutlich erweitert – etwa durch die Angabe von Schlagwörtern, dietypisch für bestimmte Kategorien sind („Beratung“ für „Mitarbeiter“, „Lieferung“ für „Produkt“ etc.). Das Ergebnis: Ein gut formulierter Prompt kann die Genauigkeit der Modelle signifikant verbessern-GPT-4 erzielte mit dem optimierten Prompt eine Accuracy von 92 % und einen F1-Score von 0,81. GPT-3 kam auf ca. 76 % Accuracy, Gemini und Deepseek lagen zwischen 72 % und 77 %.
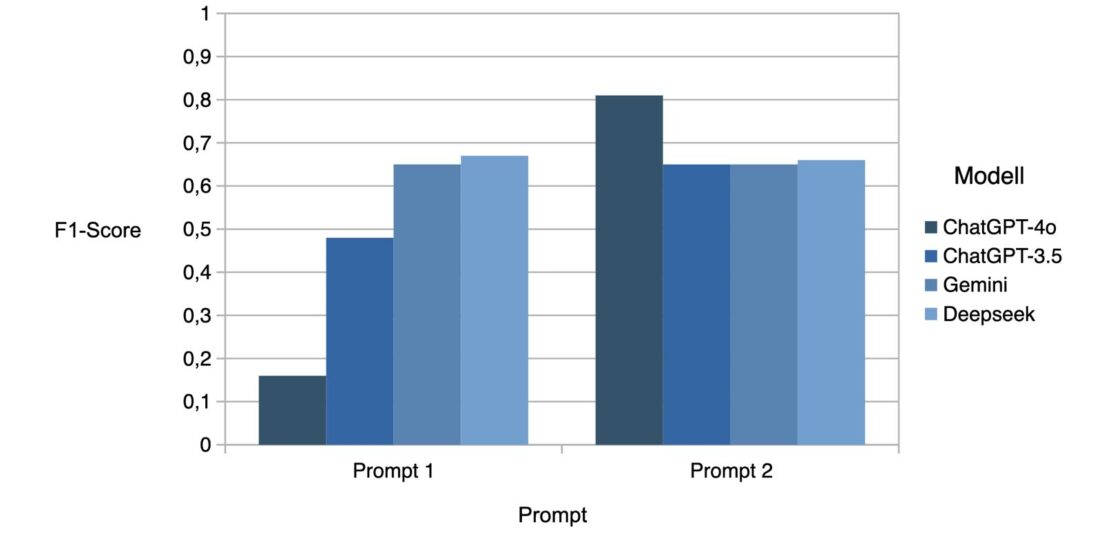
Umsetzung ML: Weniger flexibel, aber solide
Bei den ML-Modellen zeigte sich: Besonders gut funktioniert die logistische Regression – vor allem in Kombination mit einer Chi²-gewichteten Bag-of-Words-Darstellung. Die besten Ergebnisse lagen bei einem F1-Score von etwa 0,76, wenn zwei manuelle Annotationsrunden berücksichtigt wurden. Naive Bayes schnitt durchweg schwächer ab. Ein interessanter Aspekt: Ein von der KI automatisch erzeugter Goldstandard führte zu deutlich schlechteren ML-Ergebnissen (F1 ca. 0,2). Das unterstreicht, wie wichtig saubere Daten und manuelle Kontrolle bleiben.
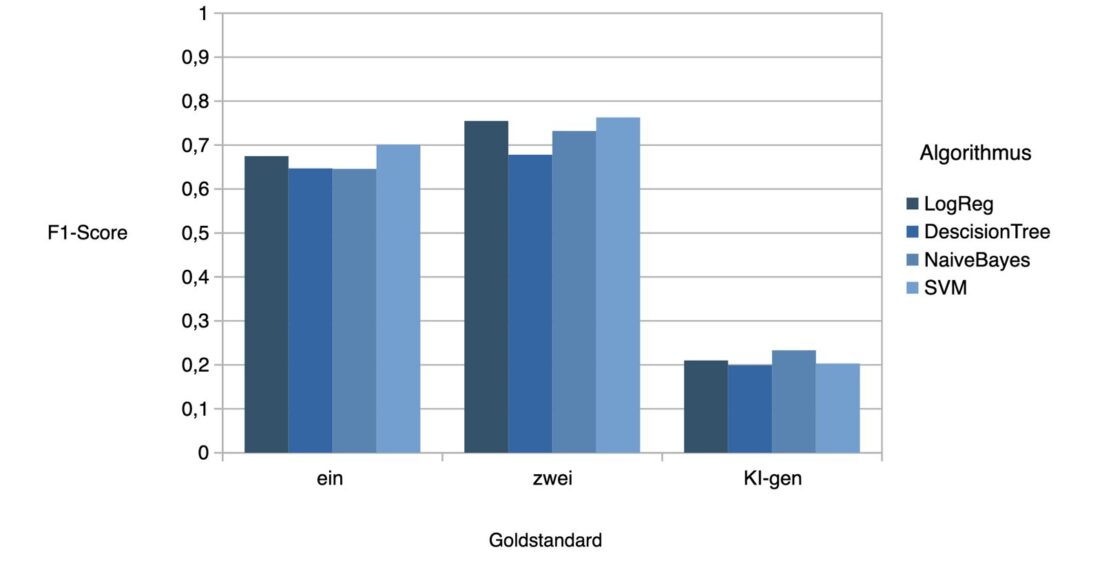
Fazit: Wann lohnt sich was?
Die Ergebnisse lassen sich pragmatisch so zusammenfassen:
- LLMs liefern sehr gute Resultate, besonders bei klarem, kurzem Feedback. Sie sind flexibel, brauchen aber gute Prompts und stabile technische Voraussetzungen (z. B. beim Datei- Upload). Sie eignen sich besonders, wenn man keine eigenen ML-Modelle aufbauen, aber dennoch schnelle Ergebnisse erzielen will.
- ML-Verfahren liefern ebenfalls gute Resultate, insbesondere bei sauberen Trainingsdaten. Sie sind lokal einsetzbar, datenschutzfreundlich und unabhängig von API-Preisen oder Modellverfügbarkeit. Für große Datenmengen oder langfristige Projekte sind sie eine solide Alternative – vor allem, wenn man eigene Ressourcen für Annotation und Modellpflege hat.
Empfehlung für Unternehmen
Wenn Sie Freitextfeedback aus NPS-Erhebungen oder anderen Quellen systematisch auswerten möchten, sollten Sie sich folgende Fragen stellen:
- Haben wir ausreichend saubere und manuell klassifizierte Daten zur Verfügung?
- Können oder wollen wir eigene ML-Modelle pflegen?
- Ist der Datenschutz ein entscheidendes Thema?
- Wie wichtig ist Flexibilität oder schnelle Skalierbarkeit?
Eine Mischung beider Welten ist denkbar: LLMs für erste Analysen oder kleinere Mengen, ML für stabile, lokal laufende Systeme. Klar ist: Ohne gute Daten und klare Kategorien funktioniert keine dieser Methoden wirklich gut.
Ausblick
Die Arbeit zeigt, dass die automatisierte Analyse von Kundenkommentaren heute keine Zukunftsvision mehr ist. Ob über LLM oder klassische ML-Modelle – beide Wege sind technisch möglich und wirtschaftlich sinnvoll, wenn sie zum jeweiligen Anwendungskontext passen. Unternehmen, die strukturiertes Feedback aus Freitexten gewinnen wollen, haben damit inzwischen mehrere praktikable Optionen zur Auswahl.