
Motivation
Für Tom Tailor nimmt das CRM eine zunehmend wichtige Rolle ein, da es eine günstigere Kundenaktivierung über “free traffic” darstellt als die Ansprache potenzieller neuer Kunden über “paid traffic”. Weiterhin wird das Online-Marketing, laut Tom Tailor aufgrund steigender Preise, stärkerer Konkurrenz und neuer Tracking- und Cookie-Regulatorik immer ineffizienter. Gleichzeitig steigt der Anspruch der Kunden nach einer guten Kunden-Händler-Beziehung. So wollen Kunden individuelle Frontends, Newsletter und Angebote erhalten. CRM-Maßnahmen sollten daher auf dem Verhalten und den Präferenzen der Kunden beruhen. Um dies zu gewährleisten, braucht es gut aufbereitete Daten, aus denen mithilfe verschiedener Datenanalyse-Strategien, inhaltlich wertvolle Erkenntnisse für die direkte Kundenansprache generiert werden können.
Rahmen der Bearbeitung
Der Kern dieses Projekts liegt darin, die Herausforderung anzugehen, datenbasierte, individuellere Kundenansprachen zu entwickeln. Für die Entwicklung der CRM Use Cases wurden eindeutige Anforderungen zusammen mit Tom Tailor definiert, um die Komplexität zu reduzieren und den Output zu verbessern:
- Die Datenbasis beschränkt sich auf die Transaktionsdaten des B2C Online Shops und wird lediglich um Produktmetadaten ergänzt.
- Die Use Cases beschränken sich auf die Kommunikation per Newsletter.
- Inhaltlicher Fokus soll auf den Affinitäten liegen, also den Präferenzen im Kaufverhalten.
- Die Use Cases sollen verschiedene Mechanismen in der Interaktion mit dem Kunden abdecken. Diese können transaktionaler (Cross-Sell, Up-Sell, Re-Buy) oder informativer Natur sein.
ETL Prozess
Die Datenanalyse ist der zentrale Bestandteil des Projektes und muss strukturiert vorbereitet werden. Optimal dafür geeignet ist ein ETL Prozess (extract, transform, load), den die Gruppe wie folgt angewandt hat.
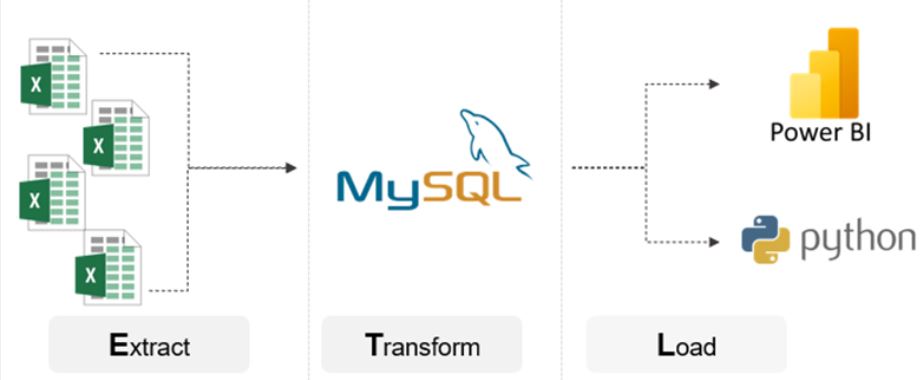
Extract (dt. Extrahieren): Der erste Schritt des Prozesses ist das Extrahieren von Daten aus den verschiedenen Quellsystemen. Die Daten lagen im CSV-Format vor und konnten so einheitlich weiterverarbeitet werden.
Transform (dt. Transformieren): Anschließend an das Extrahieren der Daten folgt die Transformation der Daten. Aufgrund der Datenmenge wurde eine eigene Datenbank in MySQL aufgesetzt, um Daten zu sichten, redundante Daten zu entfernen und Datenformate anzupassen. Zum Ende des Transformationsabschnittes erstellte die Gruppe einen finalen Export mit allen benötigten Daten, die für die eigentliche Analyse wichtig waren und exportierte diese als CSV-Datei für die anschließende, explorative Analyse.
Load (dt. Laden): Im letzten Schritt des ETL-Prozesses wurde die zuvor geprüfte und angereicherte CSV-Datei in das Analysetool Power BI geladen. Während des Importprozesses mussten einige Datenformate über den Editor angepasst und leere Zeilen sowie None-Werte befüllt und ersetzt werden.
Explorative Analyse – Power BI und Python
Zum Start der Datensichtung in Power BI wurden grundlegende Visualisierungen erstellt, um Zusammenhänge innerhalb der Daten zu erkennen und erste potenzielle Hypothesen aufzustellen, die in folgenden tiefgreifenden Analysen untersucht und somit verifiziert oder falsifiziert werden konnten.
Unter anderem wurden die Tags “Nachhaltigkeit”, “Große Größen” und “Denim” dargestellt, um ein besseres Gefühl für den Datensatz zu erhalten. Weitere Analysen in der explorative Datenanalyse gab es unter anderem zu folgenden Aspekten:
- RFM auf Kundenebene
- Anteile reduzierte Artikel, Verwendung Promotions, Kopfrabatte
- Produktfarben in Kombination mit Produktkategorie
- Umsatzverlauf der Seasons im Betrachtungszeitraum
- Top Kunden (Umsatz, bestellte Items, in Bezug auf Nachhaltigkeit)
- Verteilung der Versandarten, Endgeräte etc.
- Verteilung der Artikelgrößen und Passformen
Im Sinne der explorativen Datenanalyse konnten nach der ersten Sichtung weiterführende Felder identifiziert werden, für welche neue Kennzahlen in Form von Measures erstellt werden mussten. Diese dienten dazu, tiefergehende Zusammenhänge zu verstehen, relative Betrachtungen zu ermöglichen oder aggregierte Berechnungen zu vereinfachen. Beispiele für selbst erstellte Measures waren unter anderem:
- Durchschnittlicher Warenkorbwert auf Kunden- und Ordereben
- Anteil an gekauften nachhaltigen Produkten (auch für GG, und Denim möglich)- Summe der Umsätze auf Kunden und Order ebene (+ Summe reduzierter und unter Verwendung eines Promo-Codes generierter Umsätze)
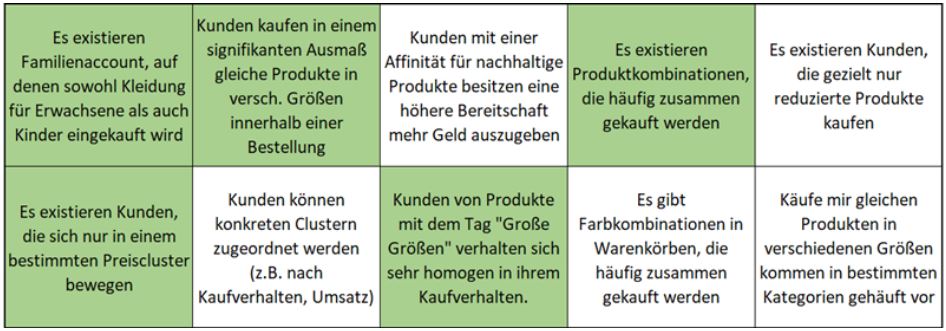
Die explorative Datenanalyse ergab unzählige Erkenntnisse, welche zunächst zusammengetragen wurden. Aus den wichtigsten Erkenntnissen wurden Hypothesen formuliert, welche es im weiteren Verlauf galt mit tieferen Analysen zu überprüfen. Die Hypothesen sind in Tabelle 1 festgehalten und beschreiben grundlegend ein konkretes Verhalten einer abgrenzbaren Kundengruppe.
Tiefenanalyse
Die Tiefenanalyse der aufgestellten Hypothesen beinhaltete u.a. die Ermittlung des Impacts, den die betroffene Kundengruppe auf den Gesamtkontext haben (absolut, relativ, monetär) sowie die genaue Abgrenzung zur restlichen Kundengruppe. Hierfür wurde neben der erneuten Verwendung von Power BI auch einige Machine Learning Algorithmen in Python verwendet
Apriori
Ziel des Apriori Algorithmus ist es, Assoziationsregeln aus Transaktionen innerhalb einer Datenbank zu erlernen. Aus diesem Grund eignet sich der Algorithmus besonders gut, um häufig vorkommende Produktkombinationen in Warenkörben zu ermitteln, wodurch Cross-Selling-Potentiale erkannt werden können. Die wichtigsten Kennzahlen bei der Betrachtung von Item Sets mit Hilfe eines Apriori Algorithmus sind der Support und die Konfidenz. Diese lassen sich wie folgt beschreiben:
- Support: misst, wie oft ein Produkt relativ gekauft wird

- Konfidenz: misst den Support für alle Transaktionen, die sowohl Produkt A und B enthalten, und teilt diesen durch den Support von Produkt A

Mittels dieser beiden Kennzahlen lassen sich Frequent Itemsets ermitteln. Diese beschreiben Elemente, die häufig zusammen innerhalb des Datensatzes auftreten und ein vorher definiertes Support- und Konfidenz-Level besitzen.
Quartilsanalyse
Die Quartilsanalyse verfolgte das Ziel, Muster im Kaufverhalten hinsichtlich der Preissegmente zu identifizieren. Die zu überprüfende Hypothese lautete: Es gibt Kunden, die lediglich Produkte aus einem Preissegment kaufen. In Absprache mit Tom Tailor wurde sich auf zwei Preissegmente (niedrig und hoch) geeinigt. Die beiden Preissegmente werden durch den Medianpreis (0,5-Quartil) aller Bestellungen einer Kategorie bestimmt. Dadurch liegen je 50% aller bestellten Artikel im niedrigen bzw. im hohen Preissegment. Der Medianpreis wurde dem Durchschnittspreis vorgezogen, welcher durch hochpreisige Ausreißer stark verzerrt werden kann. Im nächsten Schritt wurde je Kunde ermittelt, ob die Preise der einzelnen Bestellpositionen unterhalb des Medianpreises (= niedriges Preissegment) oder oberhalb des Medianpreises (= hohes Preissegment) lagen.
Use Cases
Für die im Folgenden vorgestellten Use Cases ist zu beachten, dass ein Use Case eine Basis für einen iterativen Verbesserungsprozess darstellt. Die gewonnenen Erkenntnisse der Transaktionsdaten geben vielversprechende Hinweise, wie das CRM bei Tom Tailor verbessert werden kann. Jedoch ist, für eine langfristige Betrachtung, jeder Use Case nach einer gewissen Phase zu reflektieren und zu verbessern. Auch sollten weitere Daten aus anderen Quellen hinzugezogen werden, um die Performance einzelner Use Cases auszubauen.
Use Case 1: Customer Up-Sell
Das Ziel ist es, Kunden, die vorrangig im niedrigen Preissegment kaufen, in das höhere Preissegment zu bewegen. Die technische Vorgehensweise zur Identifikation dieser Kunden wurde bereits durch die Quartilsanalyse erläutert. In der Operationalisierung gibt es zwei Ansätze, dieses Up-Selling zu verfolgen. Zum einen – im passiven Ansatz – sollten in jeglichen Newsletter Kampagnen Artikelvorschläge, die konkret einen Artikel bewerben (“Das könnte dir auch gefallen” / Cross-Selling), für die spezifische Kundengruppe immer aus dem hohen Preissegment eingebunden werden. Zum anderen – im aktiven Ansatz – kann eine eigene Up-Selling Kampagne entwickelt werden, welche aktiv dem Kunden ein höherpreisiges Produkt aus der Produktkategorie anbietet und ebenfalls einen Grund liefert, wieso dieses Produkt gekauft werden sollte. Da Tom Tailor als D2C-Händler – im Gegensatz zu einem Retailer wie AboutYou – das Up-Selling nicht über ein anderes Brand Image oder Ähnliches begründen kann, sollte hier das Material als Kaufargument im Vordergrund stehen. Insbesondere ist die Argumentation nachhaltigerer oder recycelter Materialien inhaltlich in dem Newsletter in den Fokus zu stellen.
Use Case 2: Collection Cross-Sell
Ziel der Untersuchung des Collection Cross-Sell Use Cases war es, Produkte in den beliebtesten Tom Tailor Herren Kollektionen zu identifizieren, die von Kunden oft zusammen gekauft werden, um diese dann Käufern der ermittelten Produkte gezielt in Newslettern als Form des Cross-Sellings vorzuschlagen. Auf diese Weise sollte sowohl die Conversion Rate der Newsletter gesteigert als auch die Zufriedenheit beim Kunden aufgrund der passenden Produktvorschläge gesteigert werden. Um die potenziell vorhandenen Assoziationen in den Warenkörben der Kunden zu identifizieren, nutzte die Gruppe einen Apriori-Algorithmus. Hierbei konnten einige Zusammenhänge zwischen den Kollektionen erkannt werden. So wurden z.B.:
- mit einer Wahrscheinlichkeit (Confidence) von 40,3 % Produkte der Marvin-Kollektion im gleichen Warenkorb mit Produkten aus der Aeden-Kollektion gekauft.
- mit einer Wahrscheinlichkeit von 29,9 % Produkte der Trad-Kollektion im gleichen Warenkorb mit Produkten der Marvin-Kollektion gekauft.

In der Umsetzung in Form eines Newsletters sollten dann konkrete Produkte beworben werden, die in hoher Korrelation mit bereits gekauften Produkten des Kunden stehen. Dabei kann der Kunde z. B. nach Kauf eines Artikels aus der Aedan-Kollektion einen gezielten Newsletter mit Projektvorschlägen aus der Marvin-Kollektion erhalten. Denkbar ist auch die Einbindung personalisierter Produktvorschläge in Form eines Containers, der zusätzlich in einem standardisierten Newsletter platziert wird oder einen anderen, einheitlich gestalteten Container, ersetzt.
Um den Erfolg der ausgespielten Aktionen zu beurteilen, empfiehlt die Gruppe eine gegenseitige Ausspielung von standardisierten und personalisierten Newslettern. Durch ein A/B-Testing kann der Erfolg der Newsletter dann miteinander verglichen werden.
Use Case 3: Family Cross Sell
Durch die Analyse der Daten konnten die Projektgruppe in Erfahrung bringen, dass Accounts existieren, die im Folgenden als Familienaccounts bezeichnet werden. Kunden dieser Accounts kauften im Betrachtungszeitraum vermehrt Produkte sowohl für Erwachsene als auch für Kinder. Durch eine Ausspielung personalisierten Contents, ließe sich eine Umsatzsteigerung erzielen.
Der Status quo bei Tom Tailor beinhaltet thematisch getrennte Newsletter für Männer, Frauen und gelegentlich für Kinder. Die letztgenannten waren in der Vergangenheit jedoch in ihrer isolierten Form nicht erfolgreich. Nicht zuletzt, weil eine zielgerichtete Ansprache an die Zielgruppe fehlte. Eine potenzielle Maßnahme, die Effizienz dieser Newsletter zu erhöhen, wäre die Vergabe eines Familientags an die Familienaccounts. Durch die Verleihung dieses Tags können Newsletter für betroffene Kunden dynamisch um Kids-Content ergänzt werden.
Eine Erfolgsmessung sollte mithilfe eines klassischen A/B Testing durchgeführt werden, indem eine Auswahl der Familienaccounts den dynamischen Kidscontent im Newsletter erhalten und andere nicht.
Abschließende Bewertung
Die entwickelten Use Cases haben gewisse Limitationen. Die Begrenzung der Datenquellen auf die reinen Transaktionsdaten verringert die Komplexität, jedoch würden reale Daten aus dem Tracking die Kundengruppen noch schärfer abgrenzen. Auch könnten Daten zu dem Retourenhandling die Doppelbesteller noch besser identifizieren.
Auch die Entscheidung, lediglich Transaktionsdaten von März bis Oktober zu nehmen, diente der Reduktion der Komplexität, birgt aber ebenfalls das Risiko, dass saisonale Effekte die Ergebnisse nicht repräsentativ erscheinen lassen. Die Kombination aus den Sommermonaten und der auslaufenden Corona Pandemie können auf eine Einzigartigkeit in den Daten schließen. Hier ist eine mittelfristige Reflexion der Use Cases wichtig.
Quellen:
Boychuk, A. (2023). Understanding Average Upsell Conversion Rates and Tips. Abgerufen am 21. Februar 2023 von https://flowium.com/blog/average-upsell-conversion-rates/
Daly, N. (2022). What Is a Use Case? Abgerufen am 21. Februar 2023 von https://www.wrike.com/blog/what-is-a-use-case/
Heller, D. (kein Datum). Mehr Umsatz durch Upselling und Cross-Selling: So geht’s! Abgerufen am 21. Februar 2023 von https://business.trustedshops.de/blog/upselling-und-cross-selling-mehr-umsatz/
Niklas, L. (2022). Wie funktioniert der Apriori-Algorithmus? Von https://databasecamp.de/ki/apriori abgerufen
Wuttke, L. (kein Datum). Was ist ein ETL-Prozess? Abgerufen am 21. Februar 2023 von https://datasolut.com/was-ist-ein-etl-prozess/