Aufgabe und Zielstellung:
Begründet durch die Entwicklungen im Handel ergibt sich die Personalisierung von Produktempfehlungen als ein heranwachsender, wesentlicher Erfolgsfaktor für den E-Commerce[1]. Denn eine personalisierte Produktempfehlung zahlt auf die Kundenbindung und das Realisieren von Zusatzumsätzen über Crosssellings ein. Der Erfolg von Produktempfehlungen kann durch den Onlinehändler aktiv über zwei Ansätze beeinflusst werden. Diese sind der Empfehlungsermittlungsprozess, sowie die anschließende Empfehlungspräsentation[2].
Im Rahmen einer Seminararbeit von Rico Adler und Stefan Berkenhoff wurden auf Basis des Produktempfehlungsprozesses von Alba Moda Optimierungsansätze für beide Faktoren identifiziert. In diesem Blogbeitrag sollen generelle Ansätze zur Optimierung des ersten Faktors (Empfehlungsermittlung) kurz beleuchtet werden.
Methodik & Vorgehen:
Es gibt diverse Methoden zur Empfehlungsermittlung, jedoch lässt sich der Prozess generell in drei Schritte einteilen. So müssen zur Empfehlungsermittlung mittels Informationsfilterung zuerst Daten gesammelt werden. In einem zweiten Schritt wird ein User-Präferenz-Profil für den active user (für welchen die Empfehlung ermittelt werden soll) erstellt und anschließend eine Liste mit zu empfehlenden Produkten auf Basis verschiedener statistischer Verfahren ermittelt. In einem dritten Schritt wird diese initiale Liste häufig nochmal über definierte Regeln angepasst[3]. Dieser Prozess sei Beispielhaft in folgender Abbildung dargestellt. Hierbei könnten zur Umsetzung von Schritt 2 und 3 die Komponenten des Open Source Frameworks Apache Mahout und Apache Taste verwendet werden.
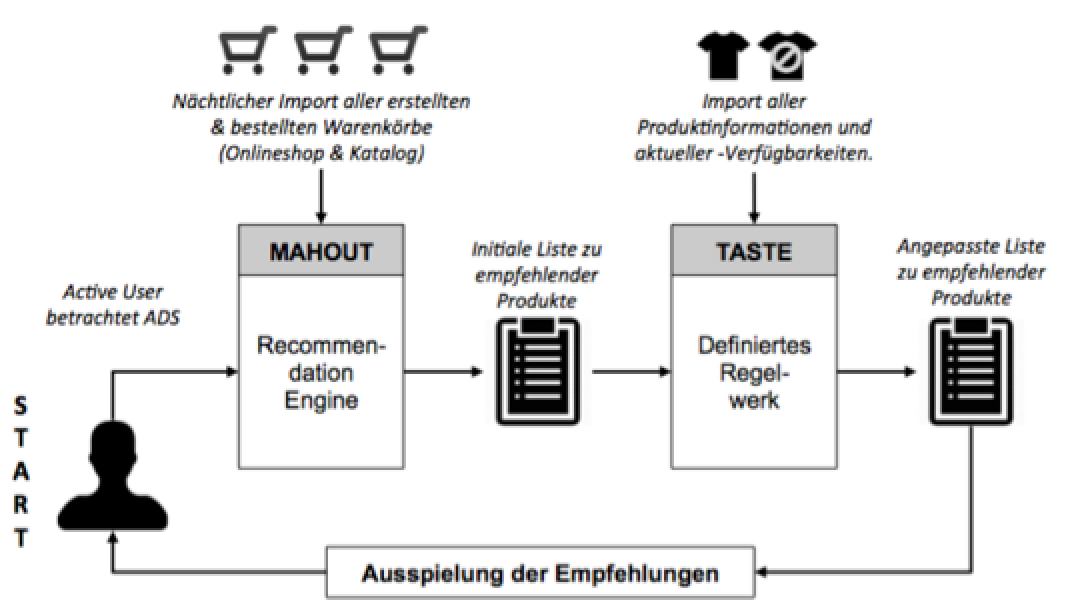
Auf Basis dieser Dreiteilung wurde die Forschungsfrage in die folgenden drei Teilfragen mit jeweils unterschiedlichen Untersuchungsansätzen heruntergebrochen.

Kernergebnisse
Inputdaten
Recommendation Engines sind intelligente Systeme, die auf Wissen in Form von Daten angewiesen sind[4]. Generell bietet sich eine Klassifizierung der Betrachtung von Inputdaten innerhalb von drei Dimensionen an[5].
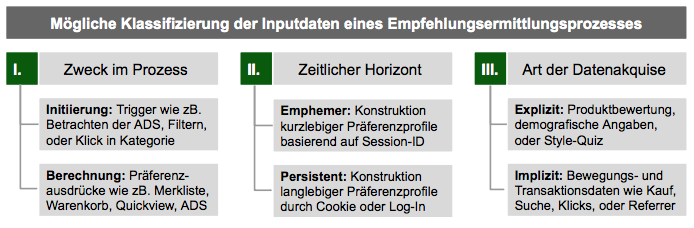
Primär stellt sich die Frage nach dem Zweck im Empfehlungsermittlungsprozess. Während bestimmte Daten zur Initiierung des Prozesses genutzt werden, dienen andere hauptsächlich zur Berechnung der Liste. Häufig wird die Initiierung über das Betrachten einer Artikel-Detail-Seite (ADS) durch den active user hervorgewirkt. Es bieten sich jedoch jegliche Daten an, die eine Aussage zur User-Präferenz treffen, wie z.B. der Klick in eine Kategorieseite, oder die Verwendung eines Filters[6] 7. Je nach statistischem Verfahren bieten sich darüber hinaus diverse Daten zur Berechnung der Liste an. Auch hier eignen sich Daten, welche Aussagen über Präferenzen treffen. So könnten Präferenzfunnel gebildet werden, wobei z.B. das Legen in den Warenkorb die höchste Präferenz bedeutet, gefolgt vom Schreiben auf die Merkliste, dem intensiven Betrachten einer ADS und ggf. dem Betrachten einer Quickview-Seite (falls vorhanden). Des Weiteren könnten Daten wie z.B. die Herkunft (Referrer des Users) genutzt werden[7].
Zusätzlich zum Zweck der Daten ist der zeitliche Horizont der Datennutzung zu bedenken, sowie ob die Daten mit aktiver Beteiligung des Users erhoben werden (explizit), oder über dessen passive Beobachtung (implizit). Eine umfangreichere Datenakquise zur Userprofilerstellung ist dabei primär für langlebige Datennutzung sinnvoll. Hinsichtlich der Art der Datenakquise sieht man häufig Kombinationen, sodass ein initiales Userprofil auf Basis expliziter Befragungen konstruiert und im Anschluss mittels impliziter Daten verfeinert wird[8].
Methode und Algorithmus
In der Literatur existieren zahlreiche weitgefasste Unterscheidungs-Taxonomien zu statistischen Methoden der Empfehlungsermittlung[9] [10], jedoch findet sich in den meisten Werken dieselbe Dreiteilung in Content-Based Filtering (CB), Collaborative Filtering (CF) und Knowledge-Based Filtering (KB)[11][12][13]. Das CB basiert das Präferenzprofil des active Users auf Item-Eigenschaften. Somit sollen ähnliche Eigenschaften von Items mit hoher Wertschätzung identifiziert werden, um Items welche diese Eigenschaften teilen empfehlen zu können[14]. Das CF kombiniert dahingegen die Präferenzprofile mehrerer User miteinander, um Ähnlichkeiten zwischen Usern abzuleiten. Somit sollen dem active user Produkte empfohlen werden, welche User mit einem ähnlichen Geschmack wertschätzten[15]. Das KB führt dahingegen zu Beginn eine umfangreiche Analyse des konkreten Userbedürfnisses durch. Hierbei muss der User das Bedürfnis häufig mittels expliziten Dateninputs konkretisieren. Im Anschluss werden über definierte Regeln Items identifiziert, die das Bedürfnis auf Basis ihrer Eigenschaften befriedigen[16]. Die drei Verfahren birgen diverse Vor- und Nachteile, welche in folgender Tabelle aufgelistet werden[17].
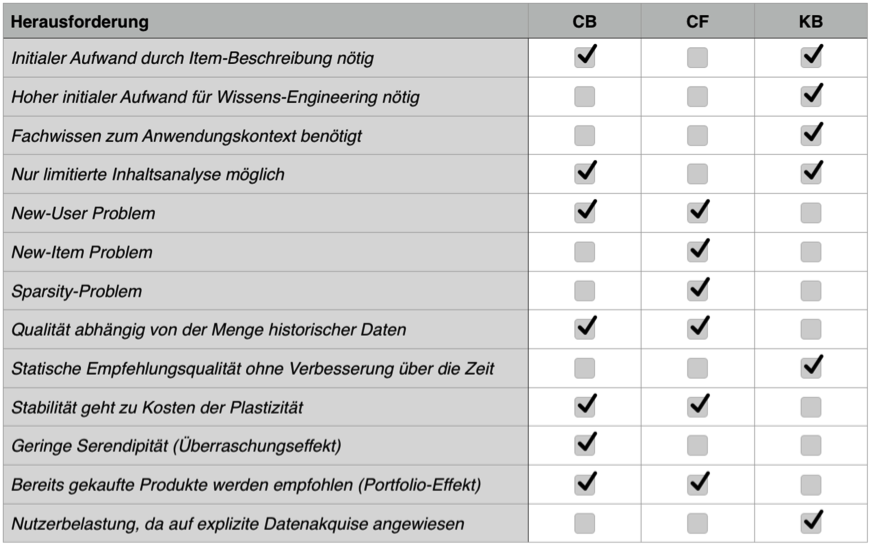
Aufgrund dieser Vor- und Nachteile werden häufig hybride Kombinationen verwendet[18]. Somit kann die Aussage über ein dominierendes Verfahren pauschal nicht getätigt werden. Ein Rahmen zur Bewertung der Eignung der Verfahren kann jedoch aus bestimmten Eigenschaften des Anwendungskontextes abgeleitet werden. So leiten Burke & Ramezani[19] aufgrund der Ausprägung von fünf Kriterien ab, welches der drei Verfahren besonders geeignet ist.
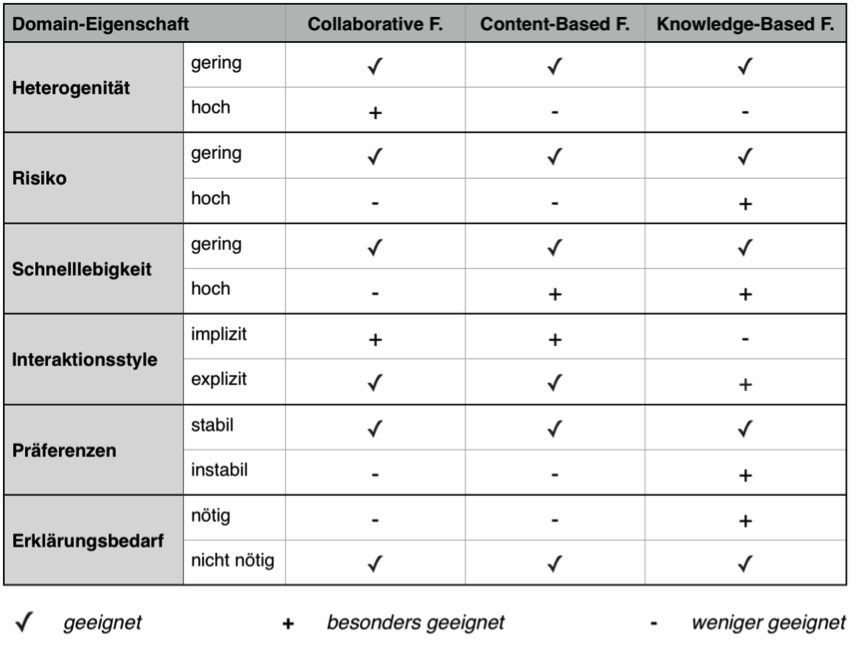
Betrachtet man z.B. einen Onlinehändler mit einem heterogenen Sortiment, welches relativ stabil ist (geringe Schnelllebigkeit), einem Fokus auf implizite Datenakquise, einer hohen Präferenzstabilität in der Zielgruppe und eher geringen Preisen (somit für den Nutzer ein geringes Risiko beim Akzeptieren einer Empfehlung, was mit geringem Erklärungsbedarf einhergeht), so bietet sich für diesen Kontext das CF am ehesten an.
In der Umsetzung des Verfahrens in einen konkreten Algortihmus gibt es jedoch diverse Optionen, zwischen denen sich entschieden werden muss. Daher sollten Kennzahlen zur Bewertung der Güte eines Algorithmus definiert und zur Konstruktion eines optimalen Algorithmus genutzt werden[20]. Eine der weitverbreitetsten Gütekriterien ist z.B. die Accuracy, welche sich über Kennzahlen wie Precision und Recall messen lässt[21]. Dieses Testing ist z.B. bei der Open Source Lösung Apache Mahout bereit implementiert.
Definierte Regeln zur Anpassung der Liste
Über Open Source Frameworks wie z.B. Apache Taste kann ein System konstruiert werden, welches die einfache Definition von Regeln zur Anpassung der initialen Recomendation-Engine Liste zulässt. Dabei beziehen sich die Regeln häufig auf das aktive Produkt, durch welches der Empfehlungsermittlungsprozess initiiert wurde (z.B. ADS angeschaut). So könnte z.B. festgelegt werden, dass Listen-Items der gleichen Marke wie das aktive Produkt um 20%, oder dass teurere Produkte 30% aufgewertet werden.
Best-Practice Analyse und Experten-Interview lieferten folgende Erkenntnisse: Es ist als sinnvoll anzunehmen, betriebswirtschaftliche Regel nicht nur auf den Preis und die Verfügbarkeit, sondern auf einen Gesamtwirtschaftlichkeitsfakor zu beziehen (z.B. bestehend aus Deckungsbeitrag, Retourquote, Lagerbestand, etc.). Des Weiteren sollten bereits empfohlene Produkte nicht kategorisch von den nächsten Empfehlungen ausgeschlossen, sondern mit einer Retargeting Logik genutzt werden.
Als hauptsächliche Erkenntnis stellte sich jedoch heraus, dass produkteigenschaftsbezogene Regeln (z.B. Marke, Farbe, Preis, Material, Schnitt, etc.) nur in Verbindung mit dem konkreten Userpräferenzprofil sinnvoll sind. Denn wertet man z.B. Items auf, nur weil diese von derselben Marke wie das aktive Produkt sind, so ist dies konträr zur angestrebten Personalisierung. Diese Regel würde z.B. nur sinnvoll sein, falls man sie entweder auf ein Präferenzprofil, oder auf eine Customer Journey über die Markenseite zum aktiven Produkt beziehen kann.
Fazit
Abschließend kann man also festhalten, dass die Empfehlungsermittlung maßgeblich von der Wahl der Inputdaten, sowie des für den Anwendungskontext geeignetsten statistischen Verfahrens abhängt. Um diese(s) Verfahren in einen optimalen Algorithmus zu überführen sollten Optimierungskennzahlen wie z.B. Precision und Recall festgelegt und genutzt werden. Und letztlich ist bei einer Anpassung der initialen Liste über (vor allem produkteigenschaftsbezogene) Regeln ein konkreter Userbezug herzustellen.
Quellen
[1] Vgl. Roggio, Armando (2015): 6 Global, Online Shopping Trends that Could Impact Your Business. Online unter: http://www.practicalecommerce.com/articles/84153-6-Global-Online-Shopping-Trends-that-Could-Impact-Your-Business
[2] Vgl. Ricci et al. (2011, S. 1ff.): Recommender System Handbook
[3] Vgl. Müller (2005, S. 36ff.): Kundenbindung im E-Commerce – Personalisierung als Instrument des Customer Relationship Marketing
[4] Vgl. Burke/Ramezani (2011, S. 382): Matching Recommendation Technologies and Domains
[5] Vgl. Knotzer (2008, S. 48ff.): Product Recommendations in E-Commerce Retailung
[6] Vgl. Düllmann / Globisch (2015): Telefonat am 11.05.2015, Interviewer: Adler, Rico; Berkenhoff, Stefan
[7] Vgl. Hamke (2015): Leitfaden-gestütztes Experteninterview vom 15.06.2015, Interviewer: Berkenhoff, Stefan; Adler, Rico
[8] Vgl. Knotzer (2008, S. 48ff.): Product Recommendations in E-Commerce Retailung Applications
[9] Vgl. Burke (2002, S. 333ff.): Hybrid Recommender Systems: Survey and Experiments,
[10] Vgl. Adomavicius/Tuzhilin (2005, S. 735ff.): Toward the Next Generation of Recommender Systems: A Survey of the State-of-the-Art and Possible Extensions
[11] Vgl. Knotzer (2008, S. 61ff.): Product Recommendations in E-Commerce Retailung Applications
[12] Vgl. Burke/Ramezani (2011,S. 371): Matching Recommendation Technologies and Domains
[13] Vgl. Belkin/Croft (1992, S. 30ff.): Information filtering and information retrieval: Two sides of the same coin
[14] Vgl. Lops/De Gemmis/Semeraro (2011, S. 75): Content-based Recommender Systems: State of the Art and Trends
[15] Vgl. Burke (2002, S. 333): Hybrid Recommender Systems: Survey and Experiments
[16] Vgl. Ricci et al. (2011, S. 12): Recommender System Handbook
[17] Vgl. Burke (2002, S. 337): Hybrid Recommender Systems: Survey and Experiments
[18] Vgl. Burke (2002, S. 337ff.): Hybrid Recommender Systems: Survey and Experiments
[19] Vgl. Burke/Ramezani (2011, S. 379): Matching Recommendation Technologies and Domains
[20] Vgl. Shani/Gunawardana (2011, S. 259): Evaluating Recommendation Systems
[21] Vgl. Herlocker et al. (2004, S. 22): Evaluating Collaborative Filtering Recommeder Systems
danke danke