
Was ist Machine Learning?
Machine Learning oder “Maschinelles Lernen” ist ein ein Teilgebiet der Künstlichen Intelligenz (engl. Artificial Intelligence) [1]. Die künstliche Intelligenz beschäftigt sich damit, Maschinen menschliche Intelligenzleistungen beizubringen.
Beim Maschine Learning kann das künstliche System mit Hilfe von Algorithmen Muster in Daten erkennen, sodass es eigenständig Lösungen finden kann. Im Machine Learning wird zwischen zwei Lernstilen unterschieden: dem überwachten und dem unüberwachten Lernen. Aus technischer Sicht unterscheiden sich die Beiden in ihrer algorithmischen Umsetzung [2].
Beim unüberwachten Lernen (engl. unsupervised learning) liegt der Fokus auf der Datenaufbereitung, denn der Algorithmus muss selbstständig aus den Daten Strukturen und Muster erkennen. Eine ausführliche Datenanalyse und Vorbereitung der Daten ist hierbei essenziell.
Beim überwachten Lernen (engl. supervised learning) müssen die zu prognostizierenden Werte (auch als “Labels” [3] bezeichnet) mitgeliefert werden. Bei diesem Lernstil werden die Daten in Trainings- und Testdaten aufgeteilt. Trainingsdaten sind die Daten, mit denen das Modell “trainiert”. Der Algorithmus erstellt ein Modell, das diese Daten generalisiert, sodass es auch auf neue Daten angewendet werden kann. Da das Modell die Testdaten nicht kennt, eignen sich diese, um das Modell zu validieren.
Machine Learning an einem Beispiel
Im Folgenden werden wir kurz ein Beispiel zum überwachten Lernen erläutern. Für den Algorithmus werden abhängige und unabhängige Variablen gebraucht.
Um zu prognostizieren, welche Bewertung auf eine Bestellung erfolgen wird haben wir einen brasilianischen E-Commerce Datensatz von Olist gewählt und mit Hilfe der zur Verfügung stehenden Ressourcen von Kaggle ein Prognosemodel zu entwickelt. Zuerst war es hierbei wichtig eine klare Struktur vorzunehmen und sich an diese zu halten. In solch einem Projekt entsteht schnell viel Programmcode über den der Überblick schnell verloren werden kann. Als äußerst hilfreich erwies sich das Vorgehen anhand von CRISP-DM. Die wesentlichen Phasen sind das Geschäftsverständnis, Datenverständnis und Datenvorbereitung, um eine Prognose überhaupt zu ermöglichen. Danach erfolgen die Modellierung, Evaluierung und Bereitstellung.
In der Phase Geschäftsverständnis geht es vor allem darum das Geschäftsziel zu verstehen und ein Projektziel sowie -ablaufplan zu definieren. Wir haben uns mit Olist, einem der führenden E-Commerce Kaufhäuser im brasilianischen Markt beschäftigt. Geschäftsziel und -tätigkeiten von Olist sind es vor allem Online Händler zu verbinden und diesen Unterstützung in der Logistik zu ermöglichen. Als Projektziel wählten wir eine Prognose die zeigt, ob eine Bestellung eine gute oder eine schlechte Bewertung erhalten wird. Die abhängige Variable entspricht hierbei der binären Klassifikation, ob es eine gute Bewertung wird. Um zu identifizieren was eine gute Bewertung ausmacht müssen die Daten in der Phase Datenverständnis analysiert werden. Abbildung 1 zeigt, dass die meisten Werte eine Bewertung von vier oder fünf aufweisen.
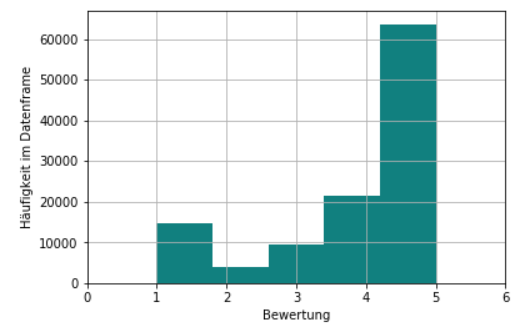
In der Phase Datenvorbereitung konnten wir nun eine Variable einführen, die positiv für diese Bewertungen (vier oder fünf) und negativ für die restlichen wird.
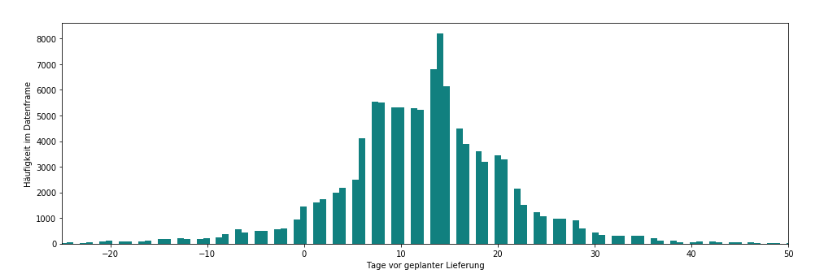
Als nächstes guckten wir uns Datumsangaben an, um mögliche unabhängige Variablen zu identifizieren – sprich Variablen, die Informationen oder Attribute enthalten, die einen Einfluss auf die abhängige Variable haben. Der Datensatz enthielt Angaben zum geplanten Lieferdatum sowie Angaben zum Zustellungszeitpunkt der Bestellung. Darauf aufbauend erzeugten wir eine Variable, die die Differenz der Anzahl der Tage zwischen diesen beiden Variablen enthält – sprich Aufschluss über die Liefergenauigkeit bietet. Aus Abbildung 2 konnten wir somit entnehmen, dass die meisten Bestellungen vorzeitig geliefert wurden und somit unter anderem die Variable “Rechtzeitige_Lieferung” einführen. Diese Variable wird positiv, wenn eine Lieferung am geplanten Liefertermin oder vorzeitig durchgeführt wurde.
Analog zu diesem Vorgehen guckten wir uns an, wann Bewertungen vorgenommen wurden und führten die Variable “Schnelle_Bewertung” ein. Diese wird positiv, sofern eine Bewertung am Tag der Lieferung oder im Zeitraum bis zu drei Tagen danach durchgeführt wurde.
In der Phase Modellierung wurden die Daten zunächst in Trainings- und Testdaten aufgeteilt. Für unser Beispiel spalteten wir die Daten in 40% Testdaten und 60% Trainingsdaten.
Unser Ergebnis ist, dass wir anhand der zwei unabhängigen Variablen „Schnelle_Bewertung“ und „Rechtzeitige_Lieferung“ die abhängige Variable „Gute Bewertung“ mit einer Genauigkeit von 80% prognostizieren können.
Abbildung 3 zeigt einen Ausschnitt der über Python erzeugten CSV-Datei, wobei neben der Order_ID die prognostizierte gute bzw. schlechte Bewertung zu sehen ist.

Das Projekt findet Ihr auf Kaggle unter folgendem Link.
Hilfestellungen für Euer erstes Machine Learning Projekt
Hilfreich ist das Aneignen von grundlegenden Machine Learning Kenntnissen z.B. mithilfe von Tutorials auf Kaggle im Learning Bereich. Solltet Ihr in Eurem Machine Learning Projekt nicht weiterkommen, könnt Ihr Hilfe auf Seiten wie Kaggle (in veröffentlichten Kernels), TowardsDataScience und StackOverflow finden, da hier viele Beispiele und Erklärungen zu Programmcodes veröffentlicht wurden.
Findet oder überlegt Euch eine eindeutige und sinnvolle Projektstruktur und führt Euer Projekt strikt anhand der gewählten Struktur durch. Es wird Euch viel Zeit sparen, wenn Ihr immer den Überblick bei viel Programmcode behaltet.
Selbst wenn Ihr mehrere Anläufe für so ein Projekt braucht, lasst Euch nicht von den Misserfolgen unterkriegen. Das Thema ist komplex und zeitaufwendig. Versucht aus den Fehlern zu lernen. Das oben genannte Beispiel konnten wir erst im zweiten Anlauf in dieser Form erstellen, nachdem wir einen anderen Datensatz (inkl. Modell) komplett verwerfen mussten.
Startet klein und überlegt Euch, welche Variablen miteinander korrelieren könnten. Nach und nach entwickelt Ihr einen gewissen Flow und sammelt viele Ideen zu den vorliegenden Daten. Versucht Euch allerdings nicht allzu sehr von Eurem festgelegten Projektziel zu entfernen. Im Endeffekt konnten wir nur zwei unabhängige Variablen finden, hatten jedoch fünf weitere Ideen, um den Datensatz weiter zu untersuchen.
Leider kam es bei unserer Zusammenarbeit auf Kaggle zu Abstürzen, Verbindungs- und Synchronisierungsproblemen, die die Arbeit zusätzlich erschwerten. Durch eine zu hohe Rechenlast, die durch zu viele Daten und rechenintensive Funktionen hervorgerufen wurde, ist unser erstes Modell häufig abgestürzt. Im Endeffekt kann man bei solchen Problemen nur wenig machen, außer Code-Sicherungen mit der Downloadfunktion auf Kaggle durchführen.
Bedenkt, dass das Erstellen und Validieren Eures Modells ein iterativer Prozess ist. Letztlich wird ein Modell nie “perfekt”, denn es arbeitet immer nur auf Grundlage Eures aktuellen Datenbestands. Ändert sich dieser (z.B. durch neue Daten), müssen die Daten erneut analysiert und ein neues Modell erzeugt werden.
Quellen:
- [1] Tutanch / Nico Litzel (2016): Was ist Machine Learning
https://www.bigdata-insider.de/was-ist-machine-learning-a-592092/
Zuletzt geprüft: 30. Januar 2019
- [2] Wikipedia (Letzte Bearbeitung Dez. 2018): Maschinelles Lernen
https://de.wikipedia.org/wiki/Maschinelles_Lernen#Algorithmische_Ans%C3%A4tze
Zuletzt geprüft: 15. Januar 2019
- [3] Olivia Klose (2015): Machine Learning (2) – Supervised versus Unsupervised Learning
http://oliviaklose.azurewebsites.net/machine-learning-2-supervised-versus-unsupervised-learning/
Zuletzt geprüft: 30. Januar 2019
Sehr schöner Artikel – auch sehr gut verständlich für jemanden der keine Erfahrung im Bereich Machine Learning hat.